Handling unique indexes on large data in PostgreSQL
A month ago, during a release to production, the feature I was working on failed to deploy due to a PostgreSQL restriction. It turned out to be a surprisingly fun and comprehensive learning moment.
Backstory
I have been working on a pretty huge release where we needed to:
- Add new functionality to our core feature.
- Remove all duplicated entities related to this feature.
- Set up unique index for text field to prevent new duplicates.
The first and second parts went fine, but I ran into trouble when creating the unique index. Fun fact: everything worked perfectly in the test and staging environments, but when I tried to release to production - that’s when I faced the issue:
ERROR: index row size 3456 exceeds btree version 4 maximum 2704 for index "test_big_index_big_text_key"
Detail: Index row references tuple (0,4) in relation "test_big_index".
Hint: Values larger than 1/3 of a buffer page cannot be indexed.
Consider a function index of an MD5 hash of the value, or use full text indexing.This message saying that I’m trying to insert pretty big row with the size of 3456 bytes into B-Tree index where the maximum size is 1/3 of PostgresSQL disk page (2700 bytes). If that sounds unfamiliar to you or you want to understand how to create unique indexes on huge data - no worries. We’ll figure out why this limit exists and how to avoid it. Let’s start with a bit of theory.
How to achieve uniqueness in database?
If you’ve ever wondered how a database enforces uniqueness, it must be able to determine whether two values are equal (comparing the row being inserted or updated against rows that already exist) - and do this efficiently. To make this work in practice, PostgreSQL provides six built-in ways to index values, allowing you to perform certain operations faster than without indexing. Let’s take a look at two of them that support equality comparisons:
- B-Tree
This is the default and most commonly used index type. Supports equality and standard operators like <, >, BETWEEN etc. Built on top of B-Tree data structure which uses sorting to enable fast lookups through a binary search algorithm.
- Hash
Index which support only equality check. Built on top of hash map data structure which provides average constant-time lookup for equality comparisons.
All other index types aren’t as good for strict equality comparison and are mostly used for more specific cases or complex data types. Please refer to indexes documentation for complete information.
What index to use?
From the unique indexes documentation, we’ll see that PostgreSQL only supports uniqueness enforcement using B-Tree indexes. But why is that? We just saw that at least two index types support equality comparisons and only one supports unique indexing. Let’s see why:
| Feature | B-Tree Index | Hash Index |
|---|---|---|
| Supports strict value comparison | Yes | Yes |
| Preserves order | Yes | No |
| Handles collisions | No (unique keys guaranteed) | Yes (collisions are everywhere) |
| Duplicate detection | Efficient by binary search algorithm and unique keys | Must check full content due to collisions |
The problem lies in the hash map data structure that the hash index uses. A hash map stores values in buckets, which can lead to collisions - different values producing the same hash. Because of this, the database would need to perform a full content comparison to check whether incoming value is unique, rather than just comparing the hashes. That’s why these indexes perform poorly when it comes to enforcing uniqueness. If you want to know more about hash maps, how they work under the hood and what is collisions: check this article.
PostgreSQL data storage structure
Knowing all that information from the top, it seemed like a good idea to use a unique B-Tree index. BUT… You can’t use it for large text fields - like in my case. In production, I tried to add a unique index to fields that had around 10,000 characters, and it failed. Let’s figure out why this happens:
- PostgreSQL stores your data in files on disk. It works directly with those files and gives us a way to interact with them through SQL.
- Those files are split into 8KB pages. Each page is a fixed-size block used to store rows or index entries.
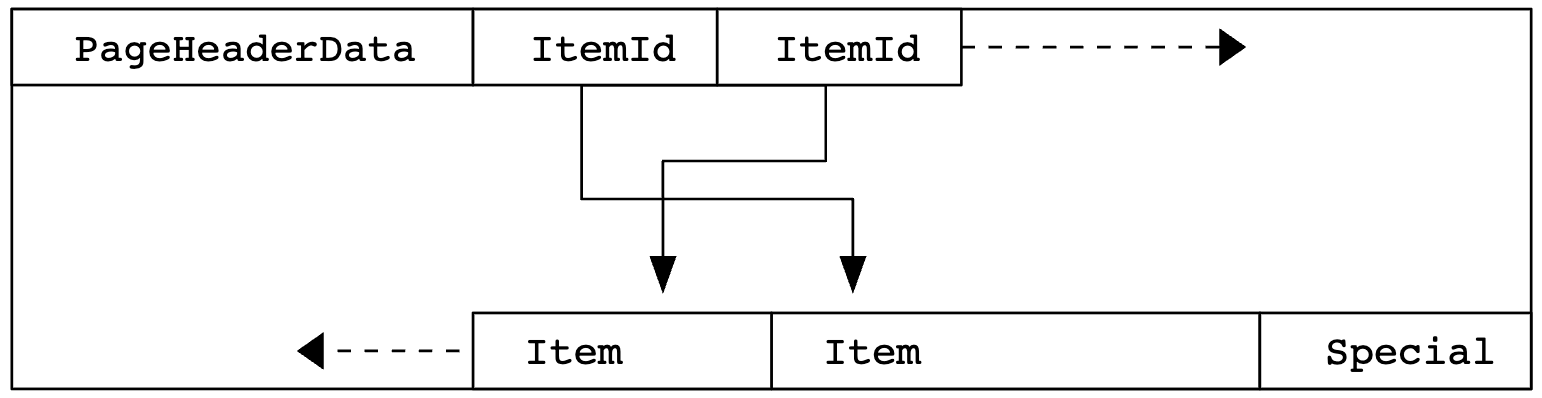
Here’s roughly how a page looks:
- Page header – stores metadata about the page
- Item pointers – pointers to the data rows
- Free space – reserved for future updates or inserts
- Data rows – the actual data we store
- Special area – (used in specific pages, like index pages, for storing additional metadata)
Here is the representation of layout from the official documentation:
This structure is interesting because PostgreSQL stores everything in 8KB pages - but we can still store field values much larger than that. So how does it work? The answer is TOAST table.
TOAST table
The TOAST stands for “The Oversized-Attribute Storage Technique”. It’s an automatic system that stores large column values in a separate TOAST table, when they don’t fit on a single 8KB page. This happens behind the scenes - you won’t usually notice it unless you’re digging deep like us right now.
You can look for TOAST table by this command:
SELECT reltoastrelid::regclass AS toast_table
FROM pg_class
WHERE relname = 'project_angle_questions';
SELECT * from <toast_table_from_above>;
# RESULT:
# |----------|-----------|---------------|
# | chunk_id | chunk_seq | chunk_data |
# | oid | integer | bytea |
# |----------|-----------|---------------|
# | 1432304 | 0 | [binary data] |
# | 1432304 | 1 | [binary data] |
Here we can see binary data that was separated from the actual PostgreSQL pages. It is stored in chunks ordered by chunk_seq, and if you combine them in the correct order, you’ll get the original data.
Problem with the large unique data
But why can’t I use a unique index on huge row data the same way I do with non-unique data - by storing it in a TOAST table?
The problem lies in sorting and PostgreSQL’s ability to perform fast random access lookups. If PostgreSQL allowed storing B-Tree index values outside the main table file (like in a separate TOAST table), then for large data rows, it would have to check the external storage each time to access the full content. That would kill performance - every insert would become an N+1 I/O operation just to confirm uniqueness.
So to keep things fast, PostgreSQL requires index entries to be stored inline, directly on the B-Tree pages. But then comes the next question: why is the limit 1/3 of the page (2.7KB) instead of just under 8KB (to leave space for metadata)?
Why 1/3 of the page is the maximum for unique B-Tree index?
Imagine this: I have a B-Tree index page with three elements, each 2.7KB. Now I’m trying to insert a fourth, also 2.7KB.
To keep the elements in order, I need to figure out where it fits - first, second, third, or fourth. But the page is already full, so PostgreSQL splits it in half and spreads the elements across two pages (two per page):
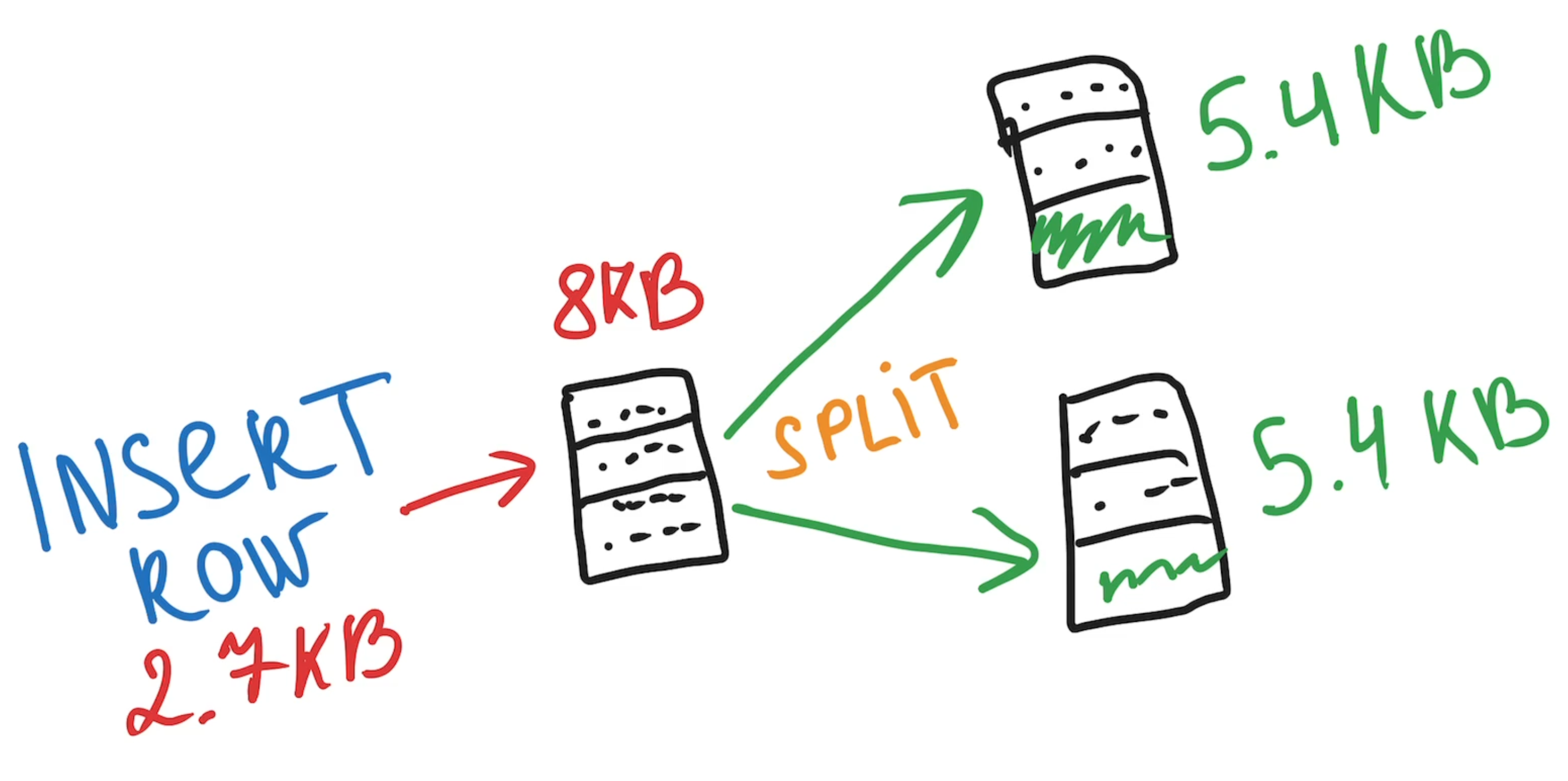
Now imagine if the maximum rows size were 4.0KB - each page could hold at most two rows. In overall it would lead to more frequent page splits and worse performance:
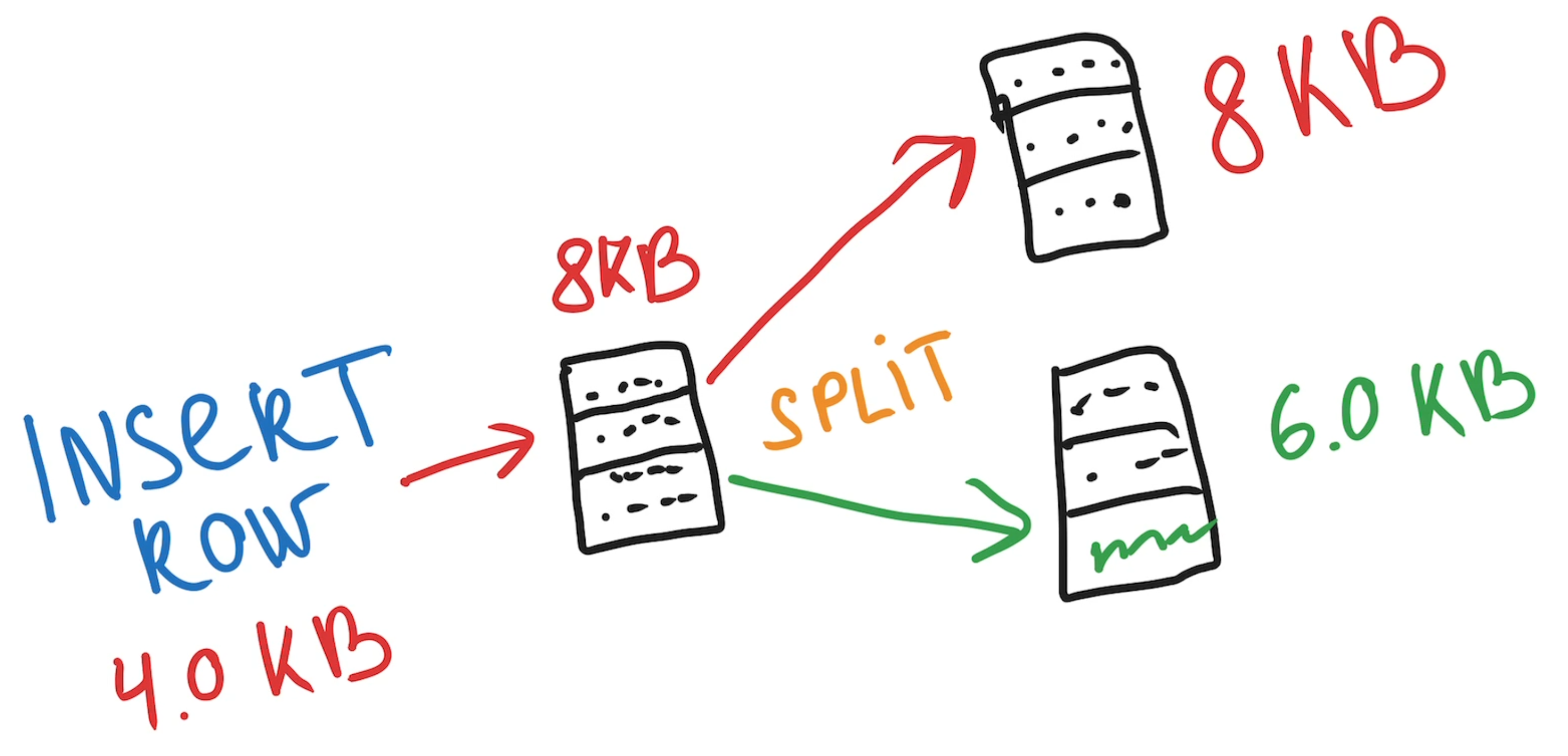
This is exactly why PostgreSQL’s developers chose an optimal balance between the maximum size of an index entry and the performance cost of splitting pages. They selected a size that keeps inserts fast while still allowing large values in unique indexes.
How to overcame such restriction
The solution is to introduce a new field that stores an autogenerated hash of the large field:
ALTER TABLE <table_name>
ADD COLUMN text_hash TEXT GENERATED ALWAYS AS (your_hash_function(text)) STORED;Hashing is the process of transforming data into a string that allows you to compare inputs, but you can’t reverse it to retrieve the original data. That’s exactly what we need, because we’re not interested in getting the original information back - we only need to check whether the data is identical or not.
There are several popular options for hashing - MD5 and SHA-256:
| Feature | MD5 | SHA-256 |
|---|---|---|
| Hash size | 128 bits (16 bytes) | 256 bits (32 bytes) |
| Speed | Faster | Slower |
| Collisions | Exists. However, the probability is so low that you won’t notice it unless your dataset exceeds 2^63 rows | No collisisons |
| Built-in support | Yes |
No (You need to install pgcrypto extension) |
Depending on your needs (speed versus reliability), you can choose between them. In our case, we used an MD5 hash because it’s fast, built-in, and our dataset isn’t large enough yet to worry about collisions.
And then, create a plain B-Tree unique index on that text hash field:
CREATE UNIQUE INDEX CONCURRENTLY IF NOT EXISTS <table_name>_text_hash_index
ON <table_name> (text_hash);Thats basically it. In such way you can avoid such constraint and store really large data inside your database even with unique constraint.
Key takeaways
- PostgreSQL has a limitation on unique index entries larger than 1/3 of a buffer page (~2.7KB).
- PostgreSQL supports 6 index types, but only B-Tree and Hash are suitable for equality comparisons on text fields. The others are optimized for more complex use cases.
- Only B-Tree indexes can enforce uniqueness. Hash indexes can’t do this efficiently because of the underlying hash map structure, which requires checking the full value in case of collisions.
- PostgreSQL stores data in 8KB pages and provides SQL tools to inspect and retrieve this raw page data.
- TOAST (The Oversized-Attribute Storage Technique) is a mechanism for storing large data values (like long text or binary) in a separate table.
- TOASTed values can’t be used in unique indexes, because it would introduce an N+1 I/O problem - the database would have to load external data for each comparison.
- The 1/3 page size limit exists to ensure efficient page splitting. When a page fills up, PostgreSQL splits it into two and reserves enough free space to allow at least one large entry on either side. 2.7KB was chosen as the optimal size by PostgreSQL developers.
- To avoid the 1/3 limit, you need to transform your data into a hash so the database can compare small fixed-size values instead of large chunks of data.