The architecture behind 99.9999% uptime in erlang
Hey there, have you ever wondered how to build the most stable application in the world? What characteristics does such an application have, and what architecture styles make it possible? It’s pretty impressive how apps like Discord and WhatsApp can handle millions of concurrent users, while some others struggle with just a few thousand. Today, we’ll take a look at how Erlang makes it possible to handle a massive workload while keeping the system alive and stable.
What’s the problem?
I believe that the best way to describe something complex is to start from the simple things and then gradually move to the complex ones. So let’s start with a simple example.
Imagine such a wonderful day:
- You are driving your Porsche Panamera and decide to call your good friend to chat about the upcoming party.
- Your phone sends a signal to the nearest cell tower.
- The network figures out the best route to reach your friend.
- The system establishes the connection and rings your friend’s phone.
- Once your friend picks up, you both start speaking and having a great time.
Everything works perfectly… until it doesn’t. While you’re driving, your phone switches to a different cell tower, and suddenly the connection drops.
Ouchhhh…
And it would be great if your broken call didn’t mess up other calls in the network (John on the other line definitely doesn’t want to deal with your issues, right?). Ideally, you’d just retry the call and keep chatting with your bro about the upcoming party.
If we turn this situation into a system design lesson, we can pull out a couple of thoughts about reliable systems:
- What you do shouldn’t hurt others in the system. In other words, things should be isolated so they don’t affect each other.
- We need mechanisms to monitor and manage those isolated things in a way that lets the system recover from unexpected failures.
At first glance, this may seem pretty simple. You can achieve something like this in almost any popular programming language. But the how is very different, and so are the feelings you get while developing and debugging such systems.
Let’s check what the options
Imagine that we are trying to build a Discord. This is a highload system which handles millions of calls simultaneously. We need to provide the best user experience so people do not leave us and go to Microsoft Teams for example. How would you build such system?
Brute force solution
Imagine you as a software engineer started working on the system, and you try to handle all calls in one main loop, like this:
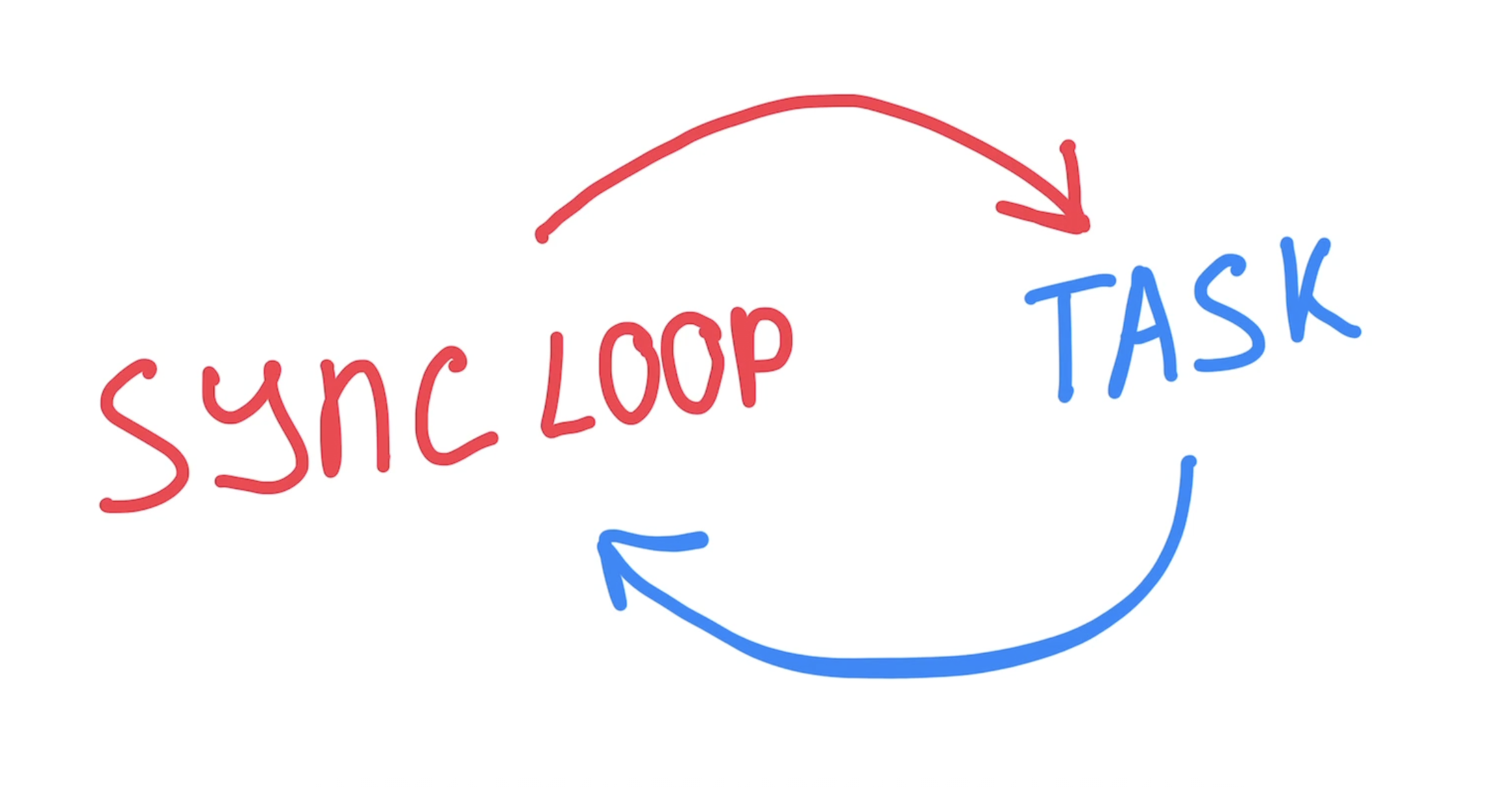
At first look, this seems pretty simple and elegant. However, in reality each call has a connection that needs to be handled. If you put all of them into a single synchronous loop, then while that loop is busy handling one call, all the other calls are forced to wait.
Next idea
Some systems allow you to create OS threads to handle work in parallel on multiple CPU cores. OS threads are small work units managed by the OS kernel that can run in the background so the main thread of the process isn’t blocked. They are scheduled preemptively, which means the OS can pause one thread and run another at any time, even on a single CPU core.
Great! You might think, “Let’s give each call its own thread!” While this seems like a simple way to run things concurrently, there are serious trade-offs:
Trade-off #1
All threads in a process share the same memory. When you share the same memory, you can have race conditions when threads trying to work on the same data in parallel: 
To prevent this, you must use the locks to the data, however it would affect how the threads are waiting for each other:
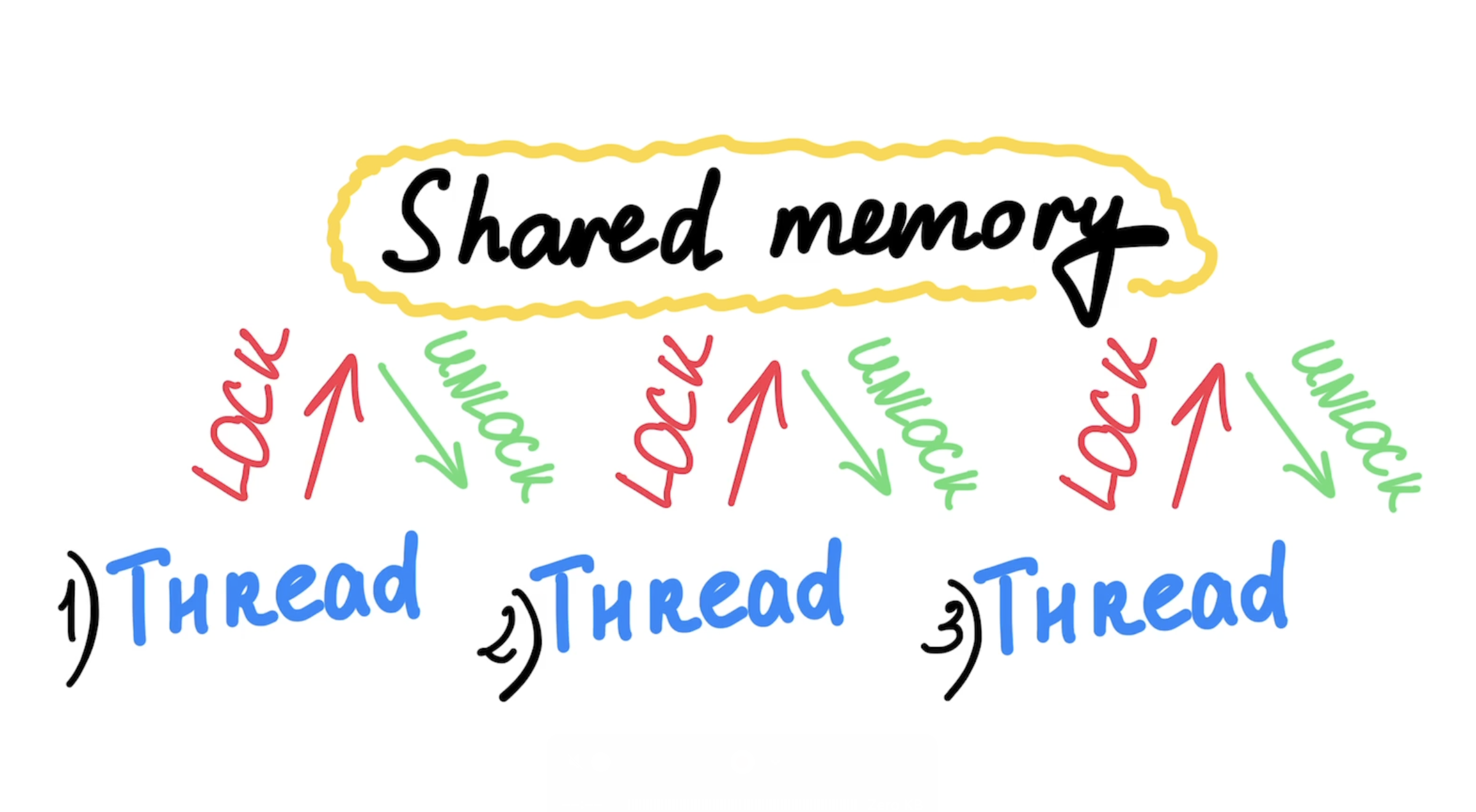
See how threads mostly waiting, not working!
Trade-off #2
Even if you used the locks, there can be a situation when one of the threads put corrupted data in the shared memory and other threads received shared corrupted data. How would you handle such case?
Trade-off #3
OS threads are really heavy in terms of memory. Each OS thread takes at least 512 KB just to exist, without doing anything. To compute how many “empty” threads you can have, just divide your RAM by the per-thread memory. It will give you amount of calls that you would have on your machine. If your machine has 8GB of available memory - it would be like 8gb / 512kb = 16,384. Huh, that’s not a millions unfortunately…
Trade-off #4
We need to observe the threads: monitor their status, track failures, and react when something goes wrong. With shared state, how would you detect issues in the system, restart only the affected processes (or all if necessary), and ensure everything keeps running smoothly? Pretty complex, right?
Better idea
What if we introduce an event-driven architecture, where your server communicates with other I/O systems via asynchronous events:
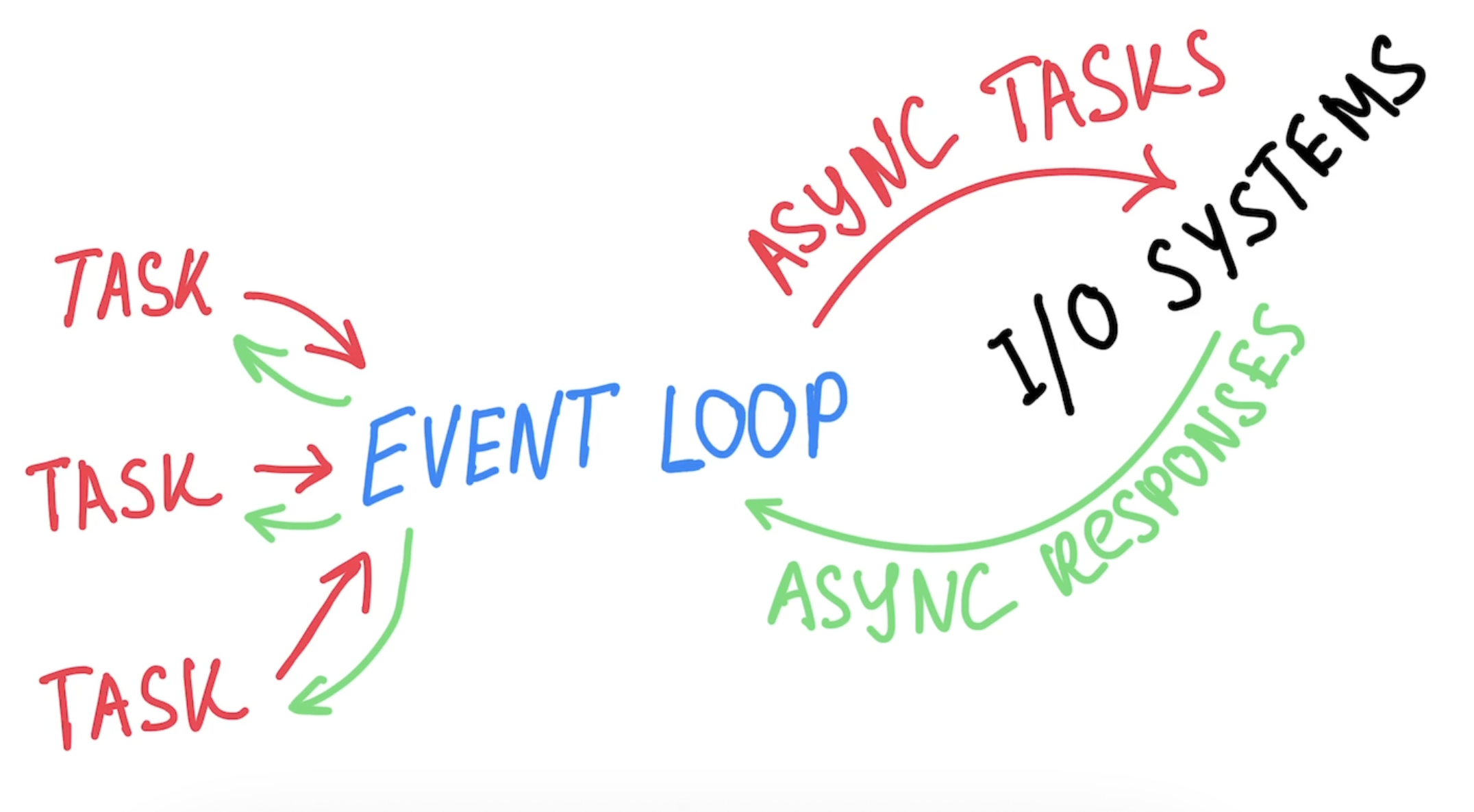 The event loop won’t be blocked by a single task, allowing you to handle thousands of them on demand, step by step. For CPU-heavy tasks you can use threads, which help prevent blocking the main thread.
The event loop won’t be blocked by a single task, allowing you to handle thousands of them on demand, step by step. For CPU-heavy tasks you can use threads, which help prevent blocking the main thread.
This kind of model already shows us why so many modern languages like Node.JS, Python lean toward event-driven design: it’s efficient and helps avoid bottlenecks. But it also leaves open questions - how do you supervise those tasks? How do you recover from failures? How do you keep track of thousands of concurrent jobs without going crazy? Only after asking those questions it becomes clear why Erlang is interesting.
How erlang solves such problems
Erlang is built on top of the BEAM virtual machine. “Virtual” means it runs on top of your operating system and provides abstractions for things like processes, scheduling and message passing.
Processes in virtual machine operate in isolated memory chunks and communicate with each other via messages (see Actor model). Think of them as people sitting in their own rooms, doing their work and sending emails to communicate (no shared memory).
The idea behind this design is that each process can fail or succeed independently, and the system can handle millions of them concurrently without affecting the others.
Let’s take a look at the main structure of each process:
- Stack – keeps track of function calls.
- Heap – stores the process internal data.
- Mailbox – a message queue that allows the process to receive messages from other processes.
- PCB (Process Control Block) – metadata about the process, used internally by Erlang.
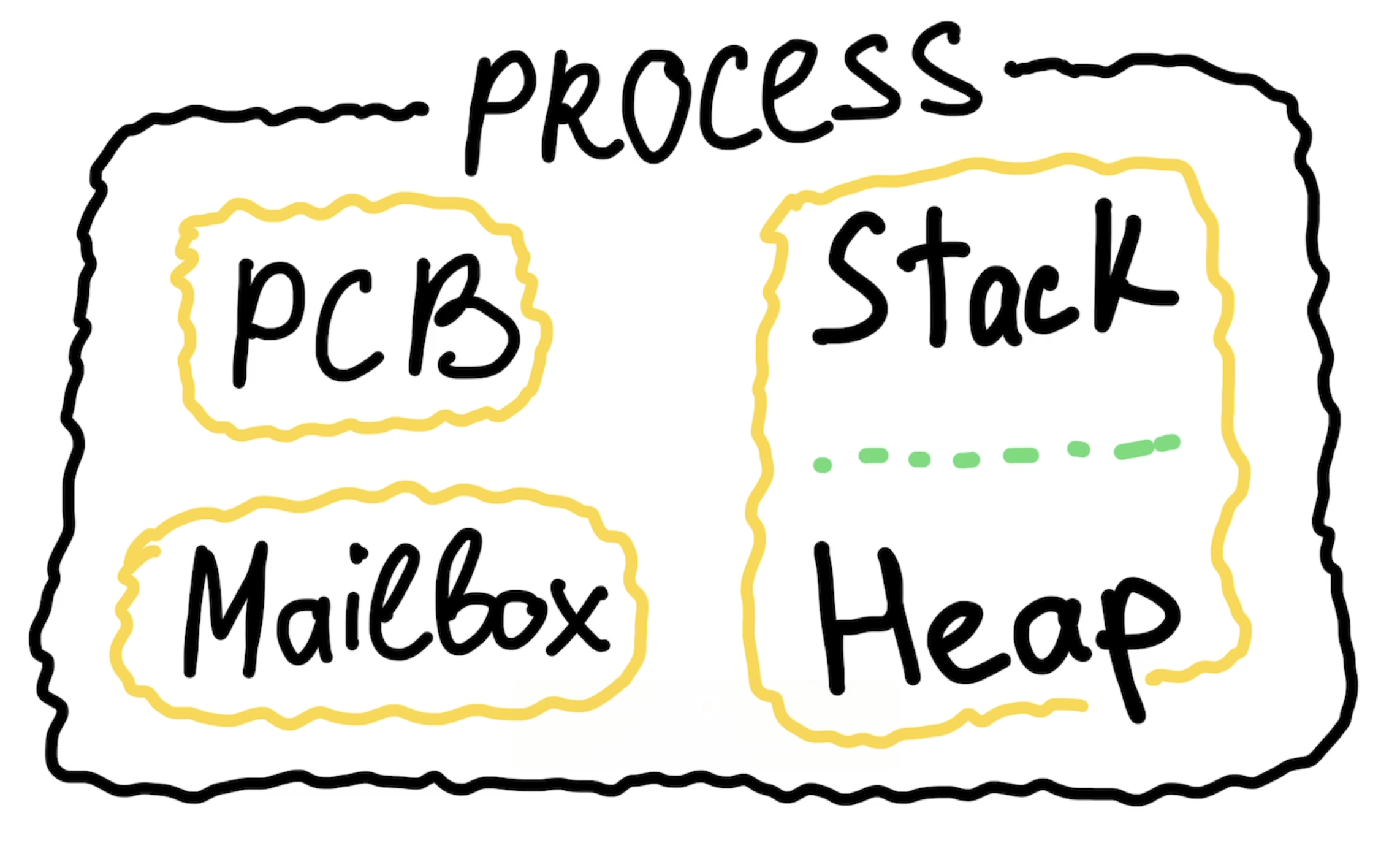
So if you want to spawn a process in the system, you’re really just creating this minimal internal structure that the BEAM needs: its unique identificator, mailbox, stack, heap, and some metadata. It’s lightweight because the process isn’t created by the OS, there is no system call and no need to touch the kernel. Instead, it’s created inside the BEAM virtual machine itself, which takes care of scheduling and managing all these processes.
In theory, creating an Erlang process takes only 327 words (where word is 4 bytes on 32-bit systems or 8 bytes on 64-bit systems), that’s the raw overhead of its internal structure from the above. Compare that to an OS thread, which usually reserves at least 512 KB (and often up to 8 MB) just for the existence.
How to observe?
If you can spawn millions of processes, the next question is: how do you keep track of them? Erlang gives you not only cheap isolated processes, but also tools to see, monitor and control them while everything is running.
You can set up relationships between these lightweight processes and define how they should behave if some of them misbehave. This feature is available as a ready-to-use abstraction in the erlang libraries (a set of generic behaviors), but it’s also something you can build on top of the features available in Erlang and extend on your own.
Imagine you’re setting up call connections on your server. Sometimes network errors happen, and you need to restart the connections until they work properly. In Erlang, with linked processes, you can catch a linked process abnormal activity and take the necessary actions yourself - for example, restart it:
-module(call).
-export([init/0]).
simulate_call(N) ->
case rand:uniform(3) of
1 ->
io:format("Call ~p dropped~n", [N]),
exit({dropped, N});
_ ->
io:format("Call ~p connected~n", [N])
end.
call_process(N) ->
receive
after 1000 ->
simulate_call(N)
end.
spawn_calls() ->
[spawn_link(fun() -> call_process(N) end) || N <- lists:seq(1, 10)].
init() ->
process_flag(trap_exit, true),
spawn_calls(),
supervise_loop().
supervise_loop() ->
receive
{'EXIT', _Pid, {dropped, N}} ->
io:format("Retrying call ~p...~n", [N]),
spawn_link(fun() -> call_process(N) end),
supervise_loop();
_Other ->
supervise_loop()
end.Here we are trying to spawn 10 calls where each can fail with equal probability and if they fail, we want to restart them until they restarted succesfully. Here is a demo:
1> call:init().
Call 1 connected
Call 2 connected
Call 3 dropped
Call 4 connected
Call 5 dropped
Call 6 connected
Call 7 connected
Call 8 connected
Call 9 connected
Call 10 dropped
Retrying call 3...
Retrying call 5...
Retrying call 10...
Call 3 connected
Call 5 dropped
Call 10 dropped
Retrying call 5...
Retrying call 10...
Call 5 connected
Call 10 connectedAnd when you have such a mechanism, you can start building more complex systems on top of it. You can create a supervision tree, where each process monitors another process using built-in behaviors in Erlang (See https://www.erlang.org/doc/apps/stdlib/supervisor). This way, every process is under control — if something goes wrong, that process can be restarted without affecting the whole system. Plus, you always have a clear picture of what’s going on in your system.
How does virtual machine schedule millions of processes?
To understand how this works, let’s go back to the early days of Erlang. The first two decades of Erlang releases, between 1986 and 2006, it supported using at most one CPU core. This means that only one process could execute at a time on that core. However, they had an ability to execute hundreds of thousands processes very fast without blocking single CPU core with long running tasks. How?
Imagine that you have a queue of waiting processes to be executed:
- Add 1 + 1
- Create an array of values from 1 to 10000
- Multiply 1 * 2
In this case we will take those processes one by one in first-in-first-out order (sorted by the date of the scheduling):
- We will execute first process - it’s pretty simple operation, and we will take only step to complete it.
-
We will execute second process - while we execute it, we see that we make array like
[1], then[1, 2], then[1, 2, 3]and so on. In some moment of time, we will understand that this task takes more operations than we would expect to complete it in one batch. In such case, for example on number 5000, we save the current call stack and step where we stop the execution for current process and intermidiate data in the process heap, and we move to another process! We don’t want to block our CPU with long running task, so we give the time for other waiting processes. - We execute third process - which is also pretty fast.
- We return to process number 2, in our heap we already have array with values from 1 to 3000, and we continue to process our array until we finish it or again we see that this process tooks a many operations to do, we pause it and give other processes their time slice.
Let’s check this in action with simple demo code, where we simulate the case from above:
-module(run_concurrently).
-export([run/0]).
run() ->
Tasks = [
fun () -> 1 + 1, io:format("Task 1 completed~n") end,
fun() -> lists:seq(1, 10000), io:format("Task 2 completed~n") end,
fun() -> 2 * 3, io:format("Task 3 completed~n") end
],
Parent = self(),
Pids = [spawn(fun() ->
Task(),
Parent ! {task_completed, self()}
end) || Task <- Tasks],
wait_for_tasks(Pids).
wait_for_tasks([]) ->
io:format("All tasks completed~n");
wait_for_tasks(Pids) ->
receive
{task_completed, Pid} ->
RemainingPids = lists:delete(Pid, Pids),
wait_for_tasks(RemainingPids)
end.And let’s try to execute it:
1> run_concurrently:run().
Task 1 completed
Task 3 completed
Task 2 completed
All tasks completed
okAs you see, all the processes get the time for their execution, and they have not blocked each other while executing long running task. I mentioned this technique earlier with OS threads — it’s called preemptive scheduling. It’s used by schedulers in both the BEAM and the OS, where each scheduler runs on a single CPU core and allocates CPU time to every task waiting to be executed.
In erlang, settings like how many function calls a process can execute before the scheduler switches to another task, along with other configuration, are stored in the Process Control Block I mentioned earlier. You can inspect them using:
1> erlang:process_info(self()) or erlang:process_info(self(), specific_field)
# And in our case to find amount of function calls a process can execute
# before the scheduler switches to another task ->
2> erlang:process_info(self(), reductions)
{reductions,8602}To check full list of the fields please visit this link: https://www.erlang.org/doc/apps/erts/erlang#process_info/2
That’s basically magic behind the concurrent processes on one CPU core. For you, as user of this system, it may looks like you running parallel execution, but in fact, they are running sequentially giving each other space to complete their work. Worth to add, that starting from May 2006, you can run multiple schedulers with multiple CPU cores. It will execute the code truly in parallel between them.
One of the features I love the most
Have you ever thought you could change a part of your application on the fly without redeploying it? Yeah, it’s like changing the tires on a moving car… but safer. And what if I told you that you can debug server processes, functions, and even add new functions to a running system without any downtime? Erlang lets you do that.
To enable hot code load functionality, Erlang has something called the code server — a process that tracks module states and can keep two versions of the same module in memory. When you load the new version into the memory - processes running the current (old) version will finish their work on that version, while processes started after a new load will run the new version. This way, you can debug and update your system very smoothly without downtime.
Also, there is a concept of release upgrades and downgrades . Basically, we can specify a rollout strategy for every release so our code doesn’t need to drop connections at all. It’s a pretty big topic because you need to manually show how to transform the state from the old version to the new version, what to do with processes that are currently running, and so on. However, on my opinion, it’s much simpler to use rolling upgrades with node restarts (which is also provides zero downtime).
Distribution
In Erlang, distribution is built right into the system. Just like you can supervise processes, you can also monitor and use other nodes. Nodes can send messages to each other or call functions remotely using RPC (Remote procedure calls), allowing you to coordinate work, handle failures, and scale across machines.
For example, you can build a cluster of nodes that share the workload via load balancing. If one node goes down, the others can seamlessly take over its tasks. Let’s build a simple load balancer to see how it works.
First of all, we will create a load balancer process responsible for getting a random node from the available list and passing it to the caller:
-module(load_balancer).
-behaviour(gen_server).
-export([start_link/1, init/1, handle_call/3, handle_cast/2]).
init(Nodes) ->
lists:foreach(
fun (Node) ->
case net_kernel:connect_node(Node) of
true ->
io:format("Connected to node ~p~n", [Node]);
false ->
io:format("Failed to connect to node ~p~n", [Node])
end
end,
Nodes
),
{ok, #{}}.
start_link(Nodes) ->
gen_server:start_link({local, load_balancer}, ?MODULE, Nodes, []).
random_strategy([]) ->
{error, no_nodes_available};
random_strategy(Nodes) ->
lists:nth(rand:uniform(length(Nodes)), Nodes).
handle_call(get_node, _From, State) -> {reply, {ok, random_strategy(nodes())}, State}.
handle_cast(_Request, State) ->
{noreply, State}.After that, we will start several nodes manually (on the cloud, this could be done automatically on demand) with specific names like these:
# First erlang node
erl -sname node1
# Second erlang node
erl -sname node2and pass them to our load balancer process as initial argument, so our nodes are aware of each other:
(node3@vova)23> load_balancer:start_link(['node1@PS-KV-MAC001', 'node2@PS-KV-MAC001']).
Connected to node 'node1@PS-KV-MAC001'
Connected to node 'node2@PS-KV-MAC001'
{ok,<0.174.0>}
We see that our erlang nodes are set up correctly and that we’re ready to route our connections. In the next step, we need to create a request_router.erl module, which will take the node received from the load balancer and perform a remote procedure call on the selected node:
-module(request_router).
-export([call/3, simple_response/0]).
call(Module, Fun, Args) ->
case gen_server:call(load_balancer, get_node) of
{ok, Node} ->
rpc:call(Node, Module, Fun, Args);
{error, no_nodes_available} ->
{error, "Server is down..."}
end.
simple_response() -> io:format('Successfull response from node ~p.~n', [node()]).Now we’re ready to accept connections and observe how the application balances requests across the available nodes:
(node3@PS-KV-MAC001)33> request_router:call(request_router, simple_response, []).
Successfull response from node 'node1@PS-KV-MAC001'.
ok
(node3@PS-KV-MAC001)34> request_router:call(request_router, simple_response, []).
Successfull response from node 'node2@PS-KV-MAC001'.
ok
(node3@PS-KV-MAC001)35> request_router:call(request_router, simple_response, []).
Successfull response from node 'node2@PS-KV-MAC001'.
ok
(node3@PS-KV-MAC001)36> request_router:call(request_router, simple_response, []).
Successfull response from node 'node2@PS-KV-MAC001'.
ok
(node3@PS-KV-MAC001)37> request_router:call(request_router, simple_response, []).
Successfull response from node 'node1@PS-KV-MAC001'.
okAs you can see, our requests are distributed randomly across the available nodes. If one of them fails, erlang detects it, removes it from the node list, and load balancer routes traffic to the remaining healthy nodes.
Conclusion
That was a lot of stuff, right? Erlang gives us so many features that in other languages would require special tooling or extra libraries. It makes communication in the system isolated, distributed, reliable, and fault-tolerant, with the ability to debug and even change code at runtime. It’s no miracle that huge, complex systems can achieve 99.999999% uptime when built with Erlang — it’s the architecture itself that allows developers to build such systems quickly and understandably.
I hope you found this article useful, maybe it even inspires you to build your first app on Erlang or Elixir. Don’t forget to subscribe, and see you next time!